
Companies with proprietary data have a unique opportunity, as well as both an obligation and a challenge.
When companies offer new and innovative tools, products and services, they have the opportunity to win more business.
The obligation is to their customers and shareholders to make the highest and best use of the data.
The challenge is in understanding what is the highest and best use of their data and how to use it.
📈 Consider an algorithm that determines the fair market values for a domain name.
People at companies have tried to solve this problem for years.
Estibot, Valuate, GoDaddy GoValue, Domain Price Checker, Saw, FreeValuator, HumbleWorth, Accurate Appraisals, Sedo, Domain Worth…the list goes on.
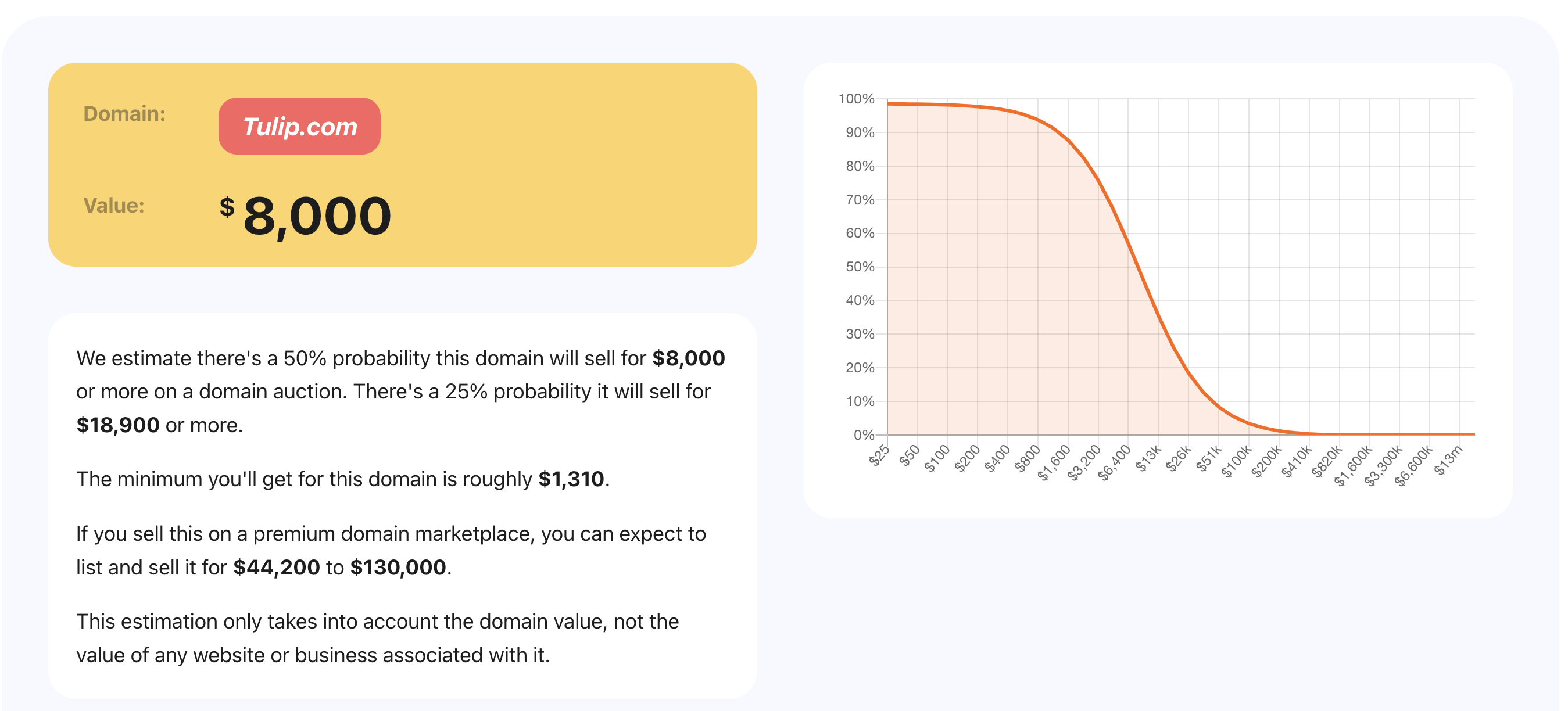
Humbleworth Valuation of Tulip.com, a domain name with a wholesale valuation much higher than $8,000
Why can’t the domain name valuation problem be solved once and for all?
The Problem Lies in the Data
Data is the foundation for learning.
Data is the source of trends, patterns and insights.
But not all data is equal, and the data must be correct.
I’m sure everyone’s heard the saying, “bad data in, bad result out.”
So will Artificial Intelligence (AI) be able to help us solve the domain name valuation problem finally by magically determining what data is good and what is bad? What data is correct and what data is incorrect?
Will AI Save the Day?
The short answer: no.
Better data is necessary.
Feeding AI outdated or irrelevant data is like expecting apple juice from oranges. It simply won’t work.
This is why tools like GoDaddy’s GoValue sometimes work and sometimes falter. They rely on a mixture of retail and wholesale transaction data, which often doesn’t reflect current retail values.
If the model happens to select good data for a subject domain, you will likely get a good result. (Good data in, good result out.) But the likelihood of every automated valuation using good data is slim.
Accurate physical real estate appraisals rely on recent, relevant, and retail data of subject properties that are properly characterized. Digital real estate appraisals are no different.
Navigating databases like NameBio can also be tricky. Without clear retail or wholesale indicators, assessing the true value of digital assets is guesswork.
What may appear to be a retail-level comparable sale to one person may in actuality be a wholesale-level comparable sale to someone who has properly characterized the domain name.
Durable Advantage for AI
Companies with proprietary data that build strong defenses against competition are the ones that will have a durable advantage.
Data is the strategic asset. It drives innovation, differentiation and value creation.
Data is the moat that guards a business; the edge that keeps competitors at bay.
And who has this quality, proprietary data?
GoDaddy likely has the largest cache of data both at wholesale levels (from GoDaddy Auctions to investors) and retail levels (from Afternic sales to end users). They know which data is more likely wholesale and retail, and knowing the buyers of the domain names can provide another level of assurance on their assessment.
NameBio has another large cache of data across the network, but has limited retail sales data and no differentiation on retail versus wholesale.
BrandBucket and Squadhelp have smaller, more niche caches of data related mostly to brandable domain names – but their data is almost entirely at the retail level.
The usable, proprietary data sets that are large enough to train and power an AI model drop-off from there.
With the right data, businesses can enhance offerings and create better customer experiences.
The challenge is to collect, categorize, clean and use proprietary data effectively.
Data will be crucial in the AI-driven future.